Towards a Large Open Video Game Dataset
Hello World!
At Open World Labs we're tackling what we think is the next big model paradigm. The early 2020s put AI into the zeitgeist: first LLMs, then text to image diffusion models, and most recently text to video diffusion models. All of these models have thus-far had their "ChatGPT" moment, when they reached a level of quality that was deserving of public interest. We believe the next big thing is going to be text-to-game world models. We also believe this new technology, when it arrives, should be developed in the open, with open source and open science at its heart. Today we are sharing our first steps as an open science lab.
The Dream
Why text-to-game world models? Our vision is that by advancing these models sufficiently, we can create the ultimate sandbox game experience. Imagine being able to prompt any experience and step directly into it, tying in any aspects you want from any game or media, the same way people do right now with text to image models. Imagine this experience being so dynamic that it can account for any choice you make, no matter how chaotically random or precisely calculated your playstyle is.
The Challenge
Training a general purpose video game generation model requires a general purpose video game dataset. Now, how can we collect such a dataset? Well, presumably there is a large intersection of people that like AI and video games. To capitalize on this fact, we set out to create an input recording software that anyone can run on their computer to record footage from their favorite video games along with keyboard and mouse inputs taken while they play. Is this a keylogger? No. Well. Yes, yes it is. But it is a keylogger with good intentions! Video was easy, we just used an OBS socket. Though that leaves one question: how can we get mouse, keyboard and controller inputs?
Input Capture (Keylogging) Is Hard
The first thought we had was to get mouse and keyboard inputs directly in python. Turns out, when you have a game open, it takes priority and python does not get any of your inputs. This took us into C, where we had to use “libuiohook” to get raw inputs. However, this also did not work, because we quickly found out that for FPS games, your mouse is always reset to the center of the screen to prevent it from going off your screen when you aim and look around. This means any high level windows API is tricked into thinking you're constantly moving the mouse in the direction of the center of the screen. In the end, the only solution was to write our own C library from scratch that got inputs directly from the users' devices. Overkill? Maybe... but it worked!
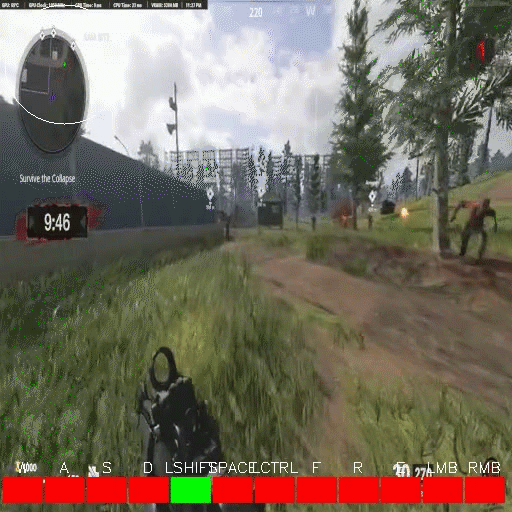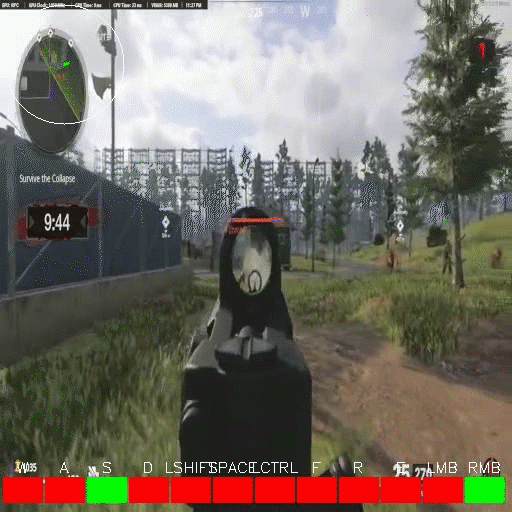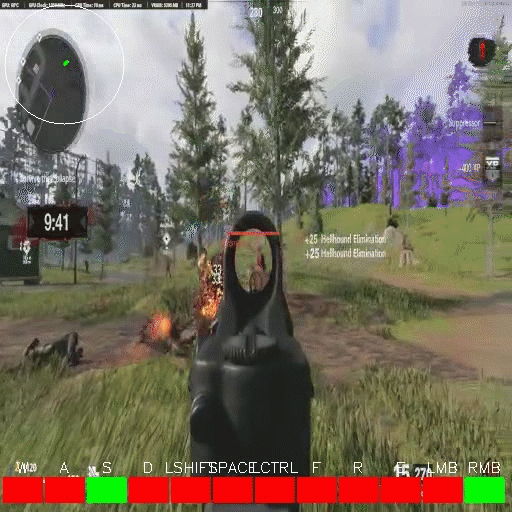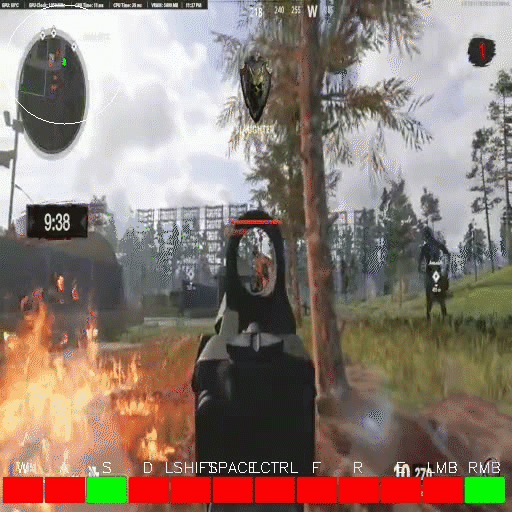
Presenting: Owl Control!
While we are still streamlining setup for a more general program, today we are releasing a developer preview for Owl Control. Owl Control is an electron app that runs in the background on your computer and connects to the Owl API. For the time being, Owl Control will only allow recording if you are playing something in following list of singleplayer FPS games:
- Doom Eternal
- Doom (2016)
- Cyberpunk 2077
- Satisfactory
- Crysis 3
- Titanfall 2
- Skyrim
- Oblivion Remastered
We will be expanding this list in the future, and if you can think of any game that would make for good data, let us know!
If you are in one of these games, and press predefined start/stop hotkeys (which you can set!), Owl Control will start recording the game with OBS, and your keyboard+mouse inputs with our C raw input reader. After you've used it more than once, it will tarball the game footage and control inputs on launch, then upload them through the Owl API. We are actively working on strategies for cleaning and curating the uploaded data, but once we have collected a large enough amount, we will be open sourcing the dataset and publishing an associated paper.
Video Data Is...
Video data is big. On the scale of even just one or two videos (especially gameplay sessions), files can get pretty big on their own. A full dataset of videos like this can become colossal (in the terabytes). At Open World Labs, we are planning on training models on thousands of hours of HD video game data, so we've been working on making some lightning fast video processing pipelines.
Suppose we are recording 1080p at 60fps.

In high quality, i.e. 25mbps, this is around 11GB per hour. That's going to stack up pretty quickly. For our pilot model we are aiming for around 512x512, so we downsample to this for the time being and reduce the bitrate to something passable: 2mbps. This gets us down to 900MB per hour.
Decoding
Next problem is loading it into PyTorch. The most straightforward approach is OpenCV's video reader, but that takes around 98s per hour of footage read. 98s to load a single sample is just too slow, and loading that into memory causes OOM issues. A partial solution here is of course to split the video into small segments, but we will get back to that shortly. For the problem of decoding, you may ask, why not use a GPU? Ironically, we found that for low res videos an average laptop CPU was faster than an H100. GPUs only help at higher resolutions (2k+). Using a large number of CPUs on a Vast AI instance, we managed to get up to a throughput of 1 hour of video decoded in 6 seconds, splitting a Decord video reader across 256 processes with an AMD EPYC 9754.
Storage and Loading
Once you've decoded all your videos into uint8 tensors, and saved them to storage, you're looking at 160 GB per hour of footage. Yikes. If we split these into 10 second segments (probably too short as is), we're looking at 1.5ms per batch element. Reframing a bit, why do we want this data? To train a latent diffusion model. For our eventual data pipeline we do not need full frames, we can just store latent frames. If we used Tiny SDXL Autoencoder we could get this down to 2.5GB if we use fp8. But... can you do that? One observation we made is that, so long as your autoencoder has numerically well behaved latents, storing the latents in fp8 e4m3 does not harm reconstruction quality at all. See below:

If you zoom in there are some artifacts, but its otherwise quite good, and there's no real drop in quality between the bf16 and fp8 latents. Of course, we aren't training on SDXL latents. It's still in the oven, but we have a model that will get an hour of footage down even further, to 400MB. We are excited to be able to share more on this soon! As far as loading goes, we can do disk i/o as a quick sanity check to see how long a 600 frame (10 seconds) segment takes to load.
| Data Format | Time To Load Samples (ms) |
|---|---|
| [3,512,512] uint8 | 1.45ms |
| [4,64,64] int8 e4m3 | 0.329ms |
| [128,16] int8 e4m3 (coming soon...) | 0.256ms |
And like that, data loading will never again be a bottleneck to model training.
Feature Extraction
As a slight aside, you know what GPUs are good for? Feature extraction! With Ray we were able to actually use those GPUs on the Vast AI instances for depth map and (WIP on visuals) optical flow estimation.


In Summary
This blog and the release of Owl Control are just us introducing ourselves to the world, and anyone interested in what we're working on. In the coming weeks, we will have a lot more to show you.
In the spirit of open science, if you want to see us building the ultimate sandbox game, or if you want to work on it as well: join us on the Open World Labs discord server.
Meet The Founders
Hey I’m Louis, CEO of OpenWorld Labs. I’m incredibly excited to be doing an open science lab, returning to my roots of decentralized research. We believe that the future of world models requires a variety of different perspectives to truly consider what is best for the community, and we’re incredibly excited to be building alongside everyone. I have half a decade in large scale open science experience and have worked at a number of large labs, previously leading CarperAI – for a time the largest open science LLM post training group, releasing what was at the time the most popular post training framework, trlX. I have also worked as Head of LLMs at Stability AI and a co-founder/member of technical staff at SynthLabs where I worked on reasoning models, tool use, and synthetic data.
Hello everyone, I'm Shahbuland: CSO of OpenWorld Labs. I've loved video games since I was two years old and my older cousins (irresponsibly) let me play Mortal Kombat on the original PlayStation. I became captivated early on by the concepts of AI and VR. I became obsessed with the dream of what I saw as the ultimate video game: A fully immersive experience, akin to a lucid dream, where you can guide the world being built around you based on your personal preferences and desires. I previously co-founded CarperAI with Louis, where I worked on representation learning and RLHF, which I continued at StabilityAI working on alignment for text-to-image models. After that I went around some startups, working on diffusion, multimodality, and world models. The last one stuck, as it seems to be the first tangible way to make my dream a reality. So now, at Open World Labs, I am building the experience I've dreamed of playing my whole life.