Towards an Even Larger Video Game Dataset: Inverse Dynamics Models For Bootstrapping Unlabelled Data

Hello Again!
It's only been a week since our last blog post, but we've already got some cool new stuff to show you! This week we've been hard at work on several things, including our first audio and video model experiments (read on for a sneak peek!), but in this blog post we will tell you about our plan to scale up our datasets beyond what is possible with crowd sourced data collection.
TL;DR
We're moving quickly to create an immersive audio/video interactive experience. Video games that generate themselves frame-by-frame as you play. Read the full post to find out how we're going to get data for it!
World Models Need...
World model need a whooole lot of data to train. Existing works like GameNGen and Oasis report needing thousands upon thousands of hours of gameplay with control labels in order to train a World Model. Since we're crowdsourcing our data, it would be kind of annoying to try and get people to play a singular game for thousands of hours. Thankfully, the internet has millions of hours of footage for video games through Twitch VODs and long YouTube playthroughs. The problem? This treasure trove of practically infinite data is entirely unlabeled. So what is one to do?
Inverse Dynamics Models: A Brief History
To learn where IDMs came from, we need to take a look at behavior cloning in robotics. The problem? Robot can't do thing humans can. The solution? Watch humans do the thing and copy them. Videos of the thing are plentiful, but the humans actions are unclear. To solve this for Minecraft, OpenAI introduced VPT , a framework that leveraged a large 500M parameter architecture trained on 2000 hours of contractor footage (with labelled video + controls) to train an Inverse Dynamics Model: a model that can predict controls from video. They used this to label a large 70,000 public Minecraft dataset and then train a small agent from that.
Simply put, this kind of approach will not cut it for our needs! 2000 hours per game is simply too much, and we also need to be able to expand to more and more games as we make our World Model more and more general. To this end, we have 4 main goals:
- The model needs to be lightweight
- It needs to be very fast to train
- The framework should generalize to training on different games
- The training pipeline should be easily deployable so we can create game-specific IDMs in a flash
We have achieved most of these this week, but are still working on a deployable training infrastructure to automatically ingest new games logged through Owl Control and IDM-ify them. Let's talk about our data-efficient and minimalist architecture!
Our Architecture

The architecture we ended up going with was very very lightweight. We ironically found making it smaller almost always made it more generalizable, and avoided the easy local minima of always predicting W (My ADHD demands that I am always moving) or predicting nothing for everything else (You certainly don't press the interact button as much as the shoot button). We dropped size to 8M, lowered resolution to 128x128, reduced temporal context to 32 frames, and lowered width substantially. While we did not try reducing the model to simple logistic regression, perhaps that is the true apex IDM? Alas we may never know.
Our final model used for labelling Call of Duty footage was 8 million parameters, trained only on 5 hours of data (at 60fps), for only a few hours on an RTX 5090.
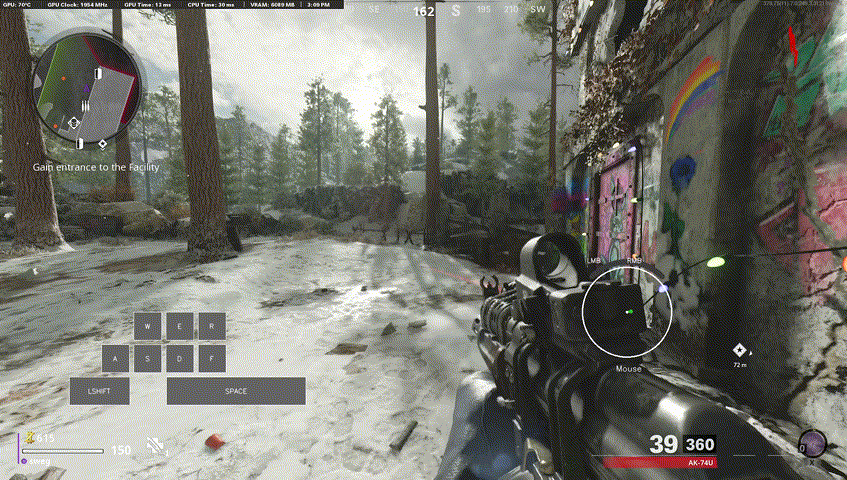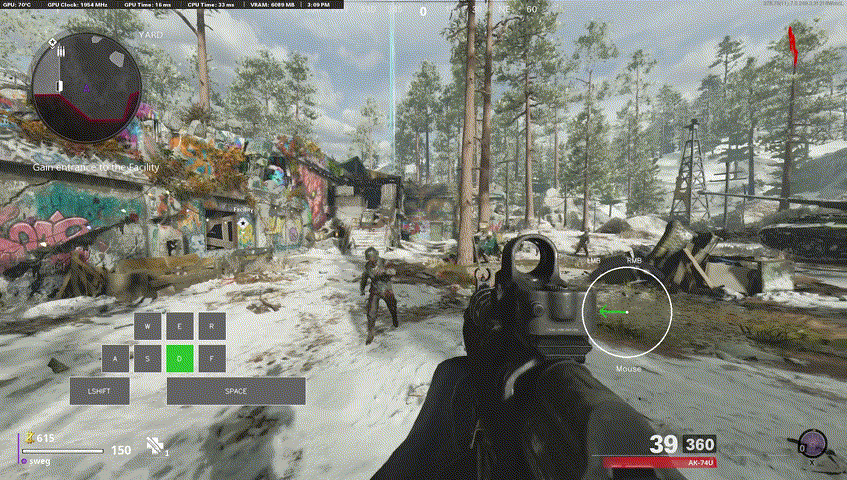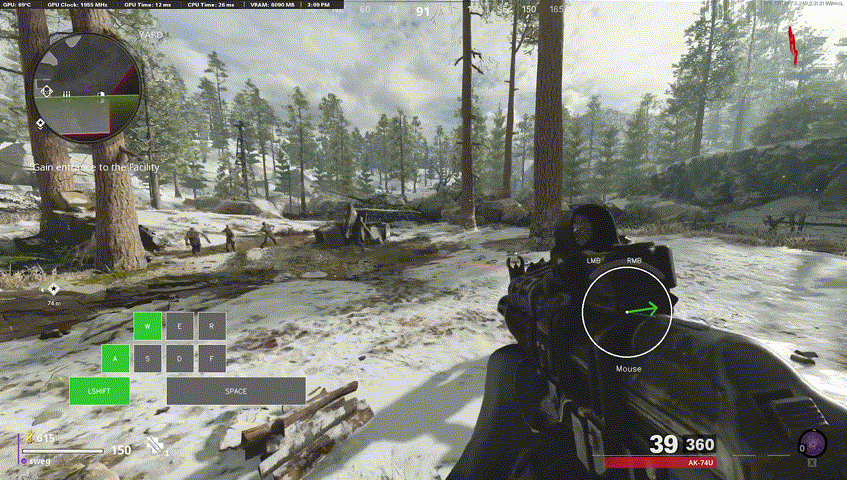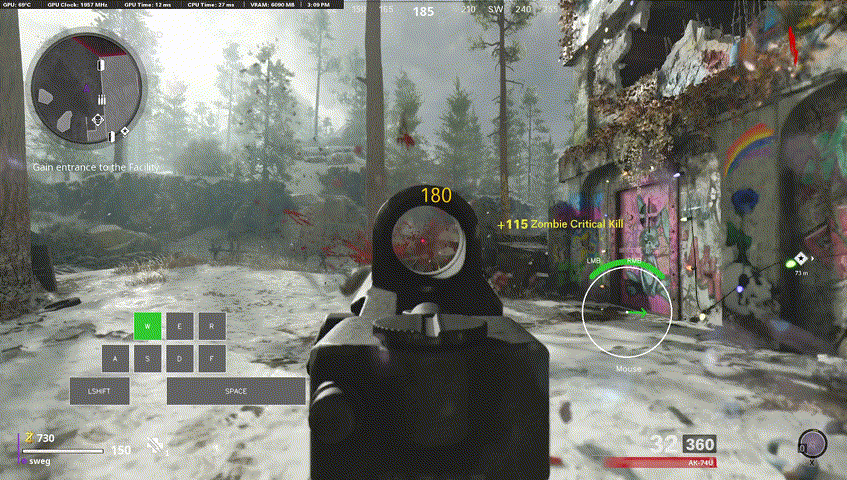
One metric we stuck with was "sensitivity", since given the number of false negatives as per the previous local minima I mentioned, true positive rate ends up being a very good measure of performance. The above model got around 90%! It generalized quite well to unseen Call of Duty gameplay but, even more impressively... it generalized to other games!

It's not perfect, but opens the door for some potential further research.
To Generalize Or To Retrain
One thing we've been actively thinking about in light of the above results is: should we train a single general purpose IDM, or keep training IDMs on a per-game basis? We think there are many details that don't generalize game-to-game (F vs E for interacting, V vs E for melee). For future work we are looking into latent actions like those used in the original Genie paper. Practical considerations in mind, we are going to stick to per-game IDMs for the time being, and speed/scale our training process up. If you want to try our model for yourself, you can download the checkpoint yourself and play around with the inference code in our OWL IDM repository.
What's Next?
Work in the OWL server moves at a breakneck pace. We have enough to show off already that we have a steady stream of weekly blog posts planned for at least the next 3 weeks. To prevent this from becoming 10+ blog posts crammed into a single page, I will list everything that is actively being worked on over the next week (yes, week singular):
- "IDM-ing" unlabelled Call of Duty Zombies footage to scale up our WM dataset. (link)
- Experimenting with generalization to see how far a single IDM can go.
- Training control conditioned video models (no WMs just yet) on our existing data. (link)
- Training equivariant VAEs for images and audio (link)
- GAN VAEs for improved sample quality
- 3D VAEs to make 3D research easier
- Improving Owl Control accessibility for non-programmers (i.e. gamers) (link)
- Scaling up and rolling out Owl Eval for comparing World Models. (link)
{kind=link}
If any of these sound interesting to you, hop on the discord server and let us know! We're always on the lookout for new volunteers.
A Look Ahead, And Some Negative Results (For Good Science!)
Next week we're going to be doing a deep dive into our experiments with VAEs. We tried to create 1D VAEs and 1D diffusion: using VAEs that compress not to a small image (ala 256x256 -> 4x4) but into a sequence of vectors (256x256 -> 16). This didn't seem to work but we have some odd findings probably worth sharing. It also gives credence to some other hypotheses I have on what makes a good VAE for diffusion but we'll save that for the blog post. We've been having a lot of technical discussions on this in the server, so if you wanna join in, feel free to hop in the #1d-diffusion channel. I am quite bummed that 1D diffusion didn't work, as it had some nice theoretical properties! However, on the bright side, it does seem like our video training setup is working, and listening to controls! (Though perhaps the inference code needs some tuning as it reeks of CFG too high...). Important note: only the second half of the frames is generated, rest is context.
